https://https://https://https://
Dans le cadre de la conception de l’identité visuelle du BRASS — Centre Culturel de Forest, nous avons développé un outil de génération automatique de documents pdf pour supports imprimés. Les fichiers pour affiches et flyers peuvent être directement créés par l’équipe du centre culturel via l’interface d’administration de leur site Internet (www.lebrass.be). Cet outil, dont la première version est utilisable par l’équipe du BRASS, sera amené à évoluer au sein de notre collaboration avec le BRASS, mais aussi, dans la mesure où il s’agit pour nous d’un premier résultat provenant d’une recherche plus large, dans la réalisation de prochains travaux.
L’objectif est multiple : profiter de la centralisation des informations relatives aux activités du BRASS sur le site (utiliser les mêmes informations encodées à la fois pour le site web et pour les supports imprimés, donc éviter les multiples encodages) ; permettre à l’équipe interne de gérer elle même la production de supports imprimés relatifs à la programmation du centre (affiches et flyers), donc ne plus dépendre de notre intervention systématique pour la production de ces supports et utiliser l’identité comme un outil ; expérimenter de nouvelles façons de produire des fichiers destinés à l’impression (tendre vers des systèmes de layout qui réagissent au contenu).
Problématique et choix des outils
Pour générer un fichier pdf directement à partir d’un site web, deux directions peuvent être prises: soit produire directement le fichier pdf à l’aide d’une librairie python (reportlab PDF toolkit) ou PHP (tcpdf), ou générer dans un premier temps un fichier html puis le convertir en pdf. C’est cette deuxième solution que nous avons choisie, pour les possibilités plus grandes que nous offrent l’html le css et le javascript dans la construction d’un layout complexe. Le projet HTML to print d’OSP nous a convaincu de nous engager dans cette voie, en ajoutant à la méthode d’OSP la conversion de l’html vers le pdf à l’aide de PhantomJS qui est un navigateur web sans interface graphique, contrôlable en javascript, qui utilise le moteur de rendu webkit et qui donne accès à une fonction de capture d’écran ou plutôt d’impression au format pdf de la page visitée.
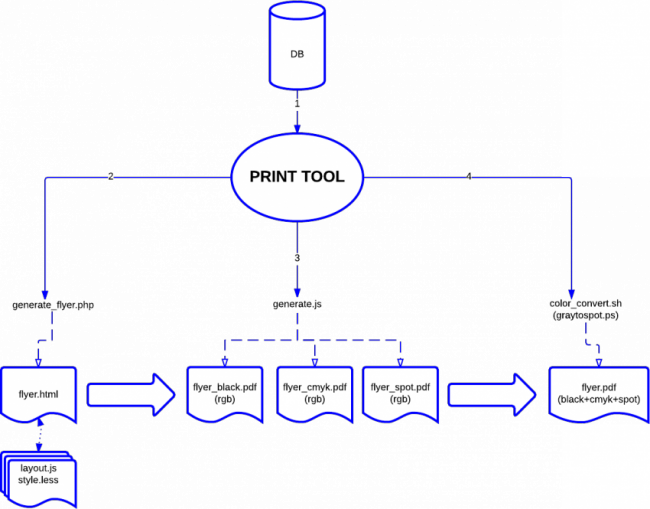
Ces choix nous ont permis de mettre en place un premier schéma d’exécution du système:
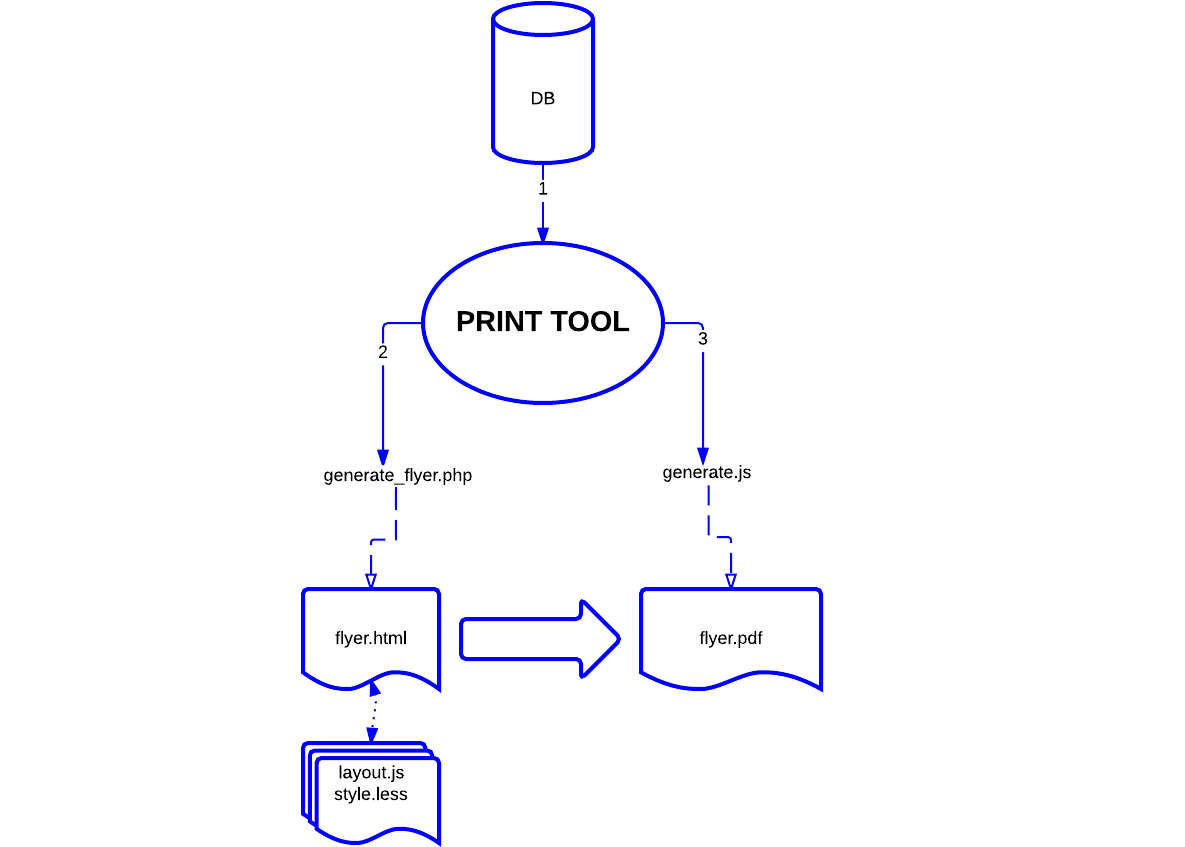
Puisque le site du Brass a été réalisé avec le CMS WordPress, la première partie du système; utiliser du contenu encodé dans le CMS pour en générer un fichier html, devait être un plugin wordpress. C’est donc le plugin (PRINT TOOL sur le schéma) qui actionne les différentes étapes du module; d’abord récupérer les informations dans la base de données, ensuite générer un fichier html (generate_flyer.php), enfin transformer ce fichier html en pdf via un script PhantomJS (generate.js).
Couleurs
Les fichiers pdf générés par PhantomJS sont en RGB. Il faut donc ajouter au processus une conversion vers CMYK pour pouvoir les destiner à une impression. Le script d’OSP rgb2cmyk.sh, qui lance une commande ghostscript pour réaliser la conversion sert justement à ça.
gs -dNOPAUSE -sDEVICE=pdfwrite -dGraphicKPreserve=2 -sColorConversionStrategy=CMYK -dProcessColorModel=/DeviceCMYK -dNOPAUSE -dBATCH -sOUTPUTFILE=output.pdf input.pdf
Si ce script suffit pour une impression en quadrichromie, il reste à trouver une solution pour les impressions en noir seul (le noir produit avec le script ci-dessus est un noir soutenu) ou en ton direct. Pour générer un fichier pdf en noir seul, il faut utiliser le DeviceGRAY au lieu du DeviceCMYK de Ghostscript. Le script devient donc
gs -dNOPAUSE -sDEVICE=pdfwrite -sColorConversionStrategy=Gray -dProcessColorModel=DeviceGray -dNOPAUSE -dBATCH -sOUTPUTFILE=output.pdf input.pdf
Mais si le fichier doit combiner du noir seul et du CMYK, cette méthode ne suffit pas puisqu’elle convertit l’entièreté du pdf en niveau de gris. La solution que nous proposons ici est de générer autant de fichiers PDF qu’il y a de modes colorimétriques différents. Un document demandant du CMYK, du noir seul et un ton direct devra être capturé par PhantomJS trois fois, pour trois fichiers pdfs différents : fichier_black.pdf, fichier_cmyk.pdf, fichier_spot1.pdf.
Capture
Les flyers pour le BRASS peuvent être en cmyk (recto) et noir (verso). Ou en PMS + CMYK (recto) et noir (verso). Le script PhantomJS va, pour chaque mode, créer un pdf. À chaque fois, il modifiera le code html du flyer pour n’afficher que les éléments correspondants au mode colorimétrique désiré.

black, cmyk, black + cmyk
Conversion
Le script de traitement des fichiers générés (black, cmyk) doit les convertir, via les deux commandes ghostscript précitées, chacun dans le bon mode colorimétrique avant de les superposer pour obtenir le pdf final (black + cmyk). La superposition se fait via l’option multistamp disponible dans l’application PDFtk
pdftk "input1.pdf" multistamp "input2.pdf" output "output.pdf"
Tons directs
Jusqu’ici, le système ne peut produire que des éléments en CMYK ou noir. Pour réussir à convertir un fichier en ton direct, il faut d’abord le convertir en niveau de gris, pour ensuite modifier le pdf généré et renseigner la référence de la couleur ainsi qu’une correspondance CMYK utilisée pour l’affichage sur écran. Pour convertir des images bitmap en ton direct, il suffit de modifier directement le code du PDF et remplacer
/ColorSpace/DeviceGray
en
/ColorSpace [/Separation/PANTONE#203295#20C/DeviceCMYK<</C0[0.0 0.0 0.0 0.0]/C1[1.0 0.0 0.529999 0.210007]/Domain[0 1]/FunctionType 2/N 1.0/Range[0.0 1.0 0.0 1.0 0.0 1.0 0.0 1.0]>>]
par exemple. Où C0 définit la couleur CMYK à afficher dans le cas où il n’y a pas d’encre (soit ici la couleur du papier) et C1 définit la couleur CMYK à afficher sur écran dans le cas d’un encrage maximal. Ces valeurs sont exprimées entre 0 et 1. Si nous nous tenons à cette modification là, les images vont être affichées en négatif parce que l’espace de couleurs DeviceGray fonctionne à l’inverse de l’espace de couleurs DeviceCMYK. Pour DeviceGray, 0 veut dire noir et 1 veut dire blanc. Pour DeviceCMYK 0 veut dire blanc et 1 la teinte au maximum de son opacité. Il faut donc modifier dans le PDF un élément supplémentaire:
/Decode[0 1]
doit devenir
/Decode[1 0]
Les éléments vectoriels (formes et typos) ne sont pas affectés par ces modifications. Pour réussir à changer la couleur de ces éléments, il va falloir passer par une étape supplémentaire : convertir le fichier pdf en niveaux de gris vers un fichier postscript avec la commande pdftops, pour enfin, transformer le fichier postscript en insérant la bonne référence couleur. Pour cela, on ajoute au fichier postscript un autre fichier postscript qui remplace les fonctions /setcolor et /setcolorspace et on reconvertit le tout en pdf. On lance donc la commande ghostscript :
gs -dNOPAUSE -dBATCH -sDEVICE=pdfwrite -sOutputFile=output.pdf ./gray_to_spot.ps ./input.ps
Qui ajoute le code contenu dans gray_to_spot.ps dans le fichier input.ps (notre fichier à convertir) avant de convertir le tout en pdf.
gray_to_spot.ps contient la réécriture des fonctions postscript nécessaires :
%spotcolor begin
/spotcolor [/Separation (PANTONE 705 U) /DeviceCMYK{dup 0.9 mul exch dup 0.1 mul exch dup 0.5 mul exch 0.1 mul}] def
%spotcolor end
/oldsetcolor /setcolor load def
/setcolor {
count
%if there is 1 value in the stack, this is a gray value
1 eq{
%we have to invert the value because
% "gray-value must be a number from 0 (black) to 1 (white)."
% "the color components must be between 0 (none) to 1 (full)."
%if there is 1 value in the stack, this is a gray value
-1 mul % =-value
1 add % =1-value
}
if
oldsetcolor
} bind def
/oldsetcolorspace /setcolorspace load def
/setcolorspace {
dup
%if the color space is gray, change it to spotcolor!
/DeviceGray eq
{
pop
spotcolor
}
if
oldsetcolorspace
} bind def
Le script bash (color_convert.sh et gray_to_spot.ps) qui combine toutes ces étapes se trouve ici : https://github.com/docteurem/PDFutils
La suite
L’approche « couche par couche » décrite nous semble une bonne solution pour les multiples modes colorimétriques devant être présents dans un et un seul pdf. La séparation de ces couches se passe, on l’a dit, au niveau de la construction de la page html. C’est précisément cette partie qu’il faut continuer à développer : comment déduire de ce travail un outil plus global, puis, et c’est là que se porte surtout notre intérêt, comment y intégrer des systèmes de layouts qui réagissent au contenu (en opposition à un système composé de templates fixes, de blocs immobiles à remplir).